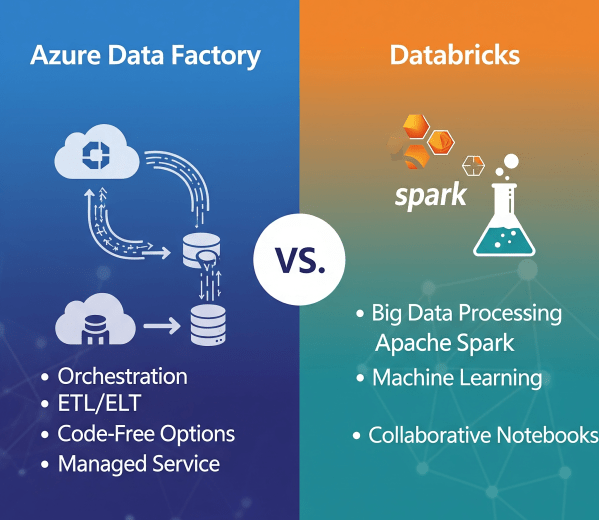
There was a time when moving data from multiple sources felt like untangling a giant knot. Every data refresh meant scripts breaking, manual checks, and long hours spent ensuring everything flowed from source to destination correctly. Then Azure Data Factory (ADF) entered the picture, and it didn’t just simplify ETL and ELT. It completely transformed how we think about data orchestration at scale.
How Azure Data Factory Changed the Way We Handle ETL/ELT at Scale