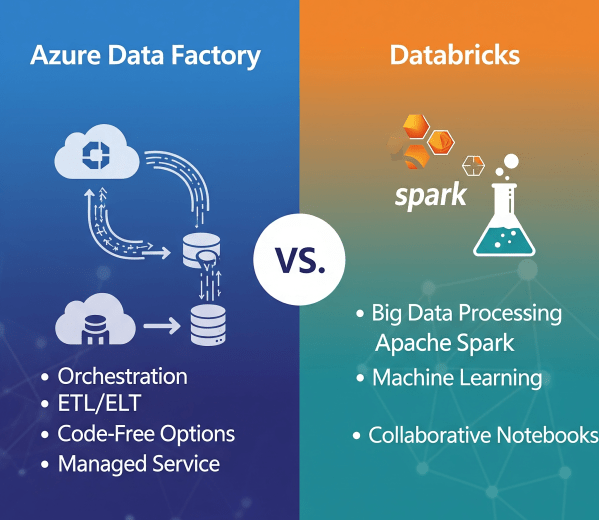
In today’s cloud-first world, enterprises have no shortage of data services. But when it comes to building scalable, reliable data pipelines, two names often dominate the conversation: Azure Data Factory (ADF) and Azure Databricks.
Azure Data Factory vs. Databricks: When to Use What?